러스트 언어의 한글
러스트 언어에서 문자열(&str, String)은 UTF-8로 인코딩 된 Unicode Scalar Value들이며, char 역시 Unicode Scalar Value를 담고 있습니다.
유니코드에서의 한글 처리에 대한 자세한 내용은 네이버 개발자 블로그(hello world)의 다음 링크를 참고해 주시기 바랍니다: 한글 인코딩의 이해 2편: 유니코드와 Java를 이용한 한글 처리
한글 자모 분리
- 이 단락은 위 링크의 글 중에서 발췌하였습니다.
일반적으로 사용하는 초성, 중성, 종성이 조합되어 있는 한글 글자(음절; Syllables)들은 가(U+AC00)부터힣(U+D7A3)의 영역에 존재합니다.
한글 음절의 코드 포인트 값은 시작 값인 U+AC00에 ((초성 값 x 21) + 중성 값) x 28 + 종성 값을 더한 것입니다.
| 값 | 초성 | 중성 | 종성 | | 값 | 초성 | 중성 | 종성 | |----|------|------|-------|--|----|------|------|------:| | 0 | ㄱ | ㅏ | 채움 | | 14 | ㅊ | ㅜ | ㄿ | | 1 | ㄲ | ㅒ | ㄱ | | 15 | ㅋ | ㅝ | ㅀ | | 2 | ㄴ | ㅑ | ㄲ | | 16 | ㅌ | ㅞ | ㅁ | | 3 | ㄷ | ㅒ | ㄳ | | 17 | ㅍ | ㅟ | ㅂ | | 4 | ㄸ | ㅓ | ㄴ | | 18 | ㅎ | ㅡ | ㅄ | | 5 | ㄹ | ㅔ | ㄵ | | 19 | | ㅢ | ㅅ | | 6 | ㅁ | ㅕ | ㄶ | | 20 | | ㅣ | ㅆ | | 7 | ㅂ | ㅖ | ㄷ | | 21 | | | ㅇ | | 8 | ㅃ | ㅗ | ㄹ | | 22 | | | ㅈ | | 9 | ㅅ | ㅠ | ㄺ | | 23 | | | ㅊ | | 10 | ㅆ | ㅘ | ㄻ | | 24 | | | ㅋ | | 11 | ㅇ | ㅛ | ㄼ | | 25 | | | ㅌ | | 12 | ㅈ | ㅙ | ㄽ | | 26 | | | ㅍ | | 13 | ㅉ | ㅚ | ㄾ | | 27 | | | ㅎ | 예를 들어, '한'이라는 글자는 'ㅎ', 'ㅏ', 'ㄴ'으로 구성되어 있으며, 각각 18, 0, 4 값을 가지고 있으므로, '한'의 코드 포인트 값은 U+AC00 + ((18 x 21) + 0) x 28 + 4 = U+AC00 + U+295C = U+D55C가 됩니다.
이를 역으로 생각해 보면, 한글 음절에 대해 초성, 중성, 종성의 분리가 가능하다. 즉 한글 음절의 코드 포인트 값에서 U+AC00을 뺀 값을 x이라 한다면, 다음과 같이 정리할 수 있습니다.
- 초성:
x의 값을 (21 x 28)로 나눈 몫 - 중성:
x의 값을 (21 x 28)로 나눈 나머지를 28로 나눈 몫 - 종성:
x의 값을 28로 나눈 나머지
러스트 언어를 사용한 구현 코드
/// 초성static CHO : [char;19] = [ 'ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ', 'ㄹ', 'ㅁ', 'ㅂ', 'ㅃ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ' ]; /// 중성static JUNG: [char;21] = [ 'ㅏ', 'ㅐ', 'ㅑ', 'ㅒ', 'ㅓ', 'ㅔ', 'ㅕ', 'ㅖ', 'ㅗ', 'ㅘ', 'ㅙ', 'ㅚ', 'ㅛ', 'ㅜ', 'ㅝ', 'ㅞ', 'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ', 'ㅣ' ]; /// 종성static JONG: [char;28] = [ ' ', 'ㄱ', 'ㄲ', 'ㄳ', 'ㄴ', 'ㄵ', 'ㄶ', 'ㄷ', 'ㄹ', 'ㄺ', 'ㄻ', 'ㄼ', 'ㄽ', 'ㄾ', 'ㄿ', 'ㅀ', 'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ' ]; /// 한글 소리마디(Hangul Syllables)를 한글 자모(Hangul Jamo)로 분리./// 다음 두 페이지를 참조하였습니다:/// * http://westzero.tistory.com/112/// * http://helloworld.naver.com/helloworld/76650fn syllables_to_jamo( string: &str ) -> Vec<char>{ let mut v: Vec<char> = Vec::new(); for c in string.chars() { let code = c as usize; if code < 0xAC00 || code > 0xD7A3 { continue; } let a = code - 0xAC00; let cho = a / (21*28); let jung = (a % (21*28)) / 28; let jong = a % (28); v.push( CHO[cho] ); v.push( JUNG[jung] ); if jong > 0 { v.push( JONG[jong] ); } } v} fn main(){ let jamo = syllables_to_jamo( "한글" ); for c in jamo { print!( "{} ", c ); }}덧붙임
한글 자모를 분리하여 이런 짓을 할 수 있습니다. 모 채널에서 뉴스 방송에 내보내어 유명해진(...) 바로 그 이름궁합입니다.
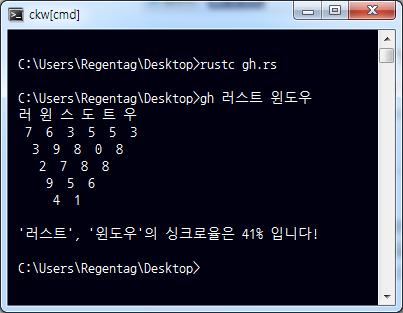
이를 통해 러스트와 윈도우의 싱크로율은 41%밖에 되지 않는다는 사실을 알 수 있습니다. 사실 반대로 돌리면 92%
이름궁합 코드는 Gist에 있습니다.


 글쓰기
글쓰기