작성자 : 동글몽실
추천 : 4
조회수 : 706회
댓글수 : 5개
등록시간 : 2016/03/13 01:23:52
충분히 큰 개체군에서 일정한 개체수 (제 1 표본)을 잡아 각 개체에 표지한 후 본래의 개체군으로 돌려보내고 일정한 기간이 지난 다음 다시 일정한 개체수(제 2 표본)을 잡아 표지된 개체수의 비를 계산한다. 마킹되어 있을 비율을 P라고 할 때
근데 이것들도 그냥 식만 딸랑 적어놓았습니다.
이해를 돕기 위한 용어들을 알았다는데 의의를 두고 모르는 용어들을 검색해봅니다. 표준오차(SE), 스튜던트 t 분포, Lincoln–Petersen estimator, Chapman estimator 등등이 뭔지 익혔습니다. 물론 maximum likelihood estimate 같이 뭔 뜻인지 이해는 하겠는데 어떻게 구하는지 모르겠는거는 나 자신과 타협하고 넘어갑니다.
다시 보았습니다. 여전히 이해가 안갑니다. 그래서 위의 문서들이 참조했다는 논문을 찾아보았습니다.
Chapter 7: Stream Fish Population Estimates by Mark-and-Recapture and Depletion Methods (Lockwood and Schneider, 2000)
Ricker, W. E. 1975. Computation and interpretation of biological statistics of fish populations. Fisheries Research Board of Canada, Bulletin 191.
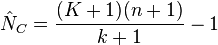
근데 또 같은 Chapman estimator를 이용하는데 문서마다 분산값이 조금씩 다릅니다.
이것도 있고

이것도 있습니다.
On Estimating the Size of Mobile Populations from Recapture Data - 1번
Improvements in the Interpretation of Recapture Data - 2번


| 출처 | 하루 빨리 검색하면 영어대신 한국어가 나왔으면 하는 나. https://en.wikipedia.org/wiki/Mark_and_recapture http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=953C72802C569180025D464E9EC75719?doi=10.1.1.214.5797&rep=rep1&type=pdf Ricker, W. E. 1975. Computation and interpretation of biological statistics of fish populations. Fisheries Research Board of Canada, Bulletin 191. http://www.jstor.org/stable/1913?seq=1#page_scan_tab_contents http://www.jstor.org/stable/2332575 |


 글쓰기
글쓰기